
[Java] Call by Value 그리고 자바의 자료형 구조.
프로그래밍 언어들의 메소드 매개변수 호출 방식에는 여러 가지가 있으며 호출 방식은 언어마다 다르게 되어 있다.
대표적인 프로그래밍 언어 중 하나인 C언어는 Call by Reference를 사용한다고 한다.
자바의 경우, 형태적으로 헷갈릴 수는 있지만 공식적으로 Call by Value 방식'만'을 사용한다.
하지만 그 과정에서 객체를 넘겨 Call by Reference와 비슷한 형태를 띄고 있을 때가 있어 헷갈릴 수 있다.
개념적으로
Call by Value는 함수의 인자를 전달할 때 '값을 전달하는 방식'이며
Call by Reference는 '주소를 전달하는 방식' 이다. 여기서 주소라 함은, 인스턴스 변수가 생성되면서 heap 영역에서 만들어지는 가상의 adress를 의미한다. 자바는 후자를 지원하지 않기 때문에 사실상 전자의 설명에 중점을 두고 있다.
우선 이 개념을 이해하기 위해 자바의 자료형 구조를 원론적으로 이해해야만 했다.
* 자바의 자료 구조

원시 자료형(Primitive Data Types)
| 자료형 분류 | 타입 이름 | 사이즈 | 범위 |
| Boolean 타입 | boolean | 1 bit | True, False |
| Integer 타입(정수) | byte | 8 bits | -128~127 |
| short | 16 bits | (3만 사이) -32,768~32,767 | |
| int | 32 bits | (20억 사이) -2,147,483,648~2,147,483,647 | |
| long | 64 bits | 900경 사이 | |
| Floating-Point 타입(실수) | float | 32 bits | 소수점 7자리 이하 |
| double | 64 bits | 소수점 16자리 이하 | |
| Character 타입 | char | 16 bits | 아스키코드 0 ~ 256 |
* 주의해야 할 것. 흔히 문자열 생성을 위해 사용하고 있는 String 은 원시 자료형이 아니다 ★★★
참조 자료형(Non-Primitive Data Types)
ex) String // Class // Array // Interface ... etc
그리고 Call by Value / Call by Reference 를 이해하기 위해 자료형을 알아야 하는 이유는
원시 자료형과
참조 자료형이
데이터를 저장하는 방식이 다르기 때문이다.
원시 자료형의 경우, 순수한 "값" 자체를 메모리(Stack) 에 저장한다.
참조 자료형의 경우 메모리에는 "Heap 주소"를 메모하고, Heap 메모리에 값을 저장한다.
그림으로 표현하면 아래와 같다.

int 라는 원시 자료형에 a라는 이름을 부여하고, 0이라는 값을 할당했다.
이 때, a = 0; 이라는 메모리, 기억은 Stack 메모리에만 기록된다.
하지만 String 이라는 참조 자료형에 value 라는 이름(객체)를 부여하고, 그 안에 "0"이라는 값을 할당했다.
이 경우 가장 먼저 값에 해당하는 "0" 이 담긴 heap 메모리가 생성되고, 임의의 주소값이 만들어진다.
(이 순서도는 틀릴 수도 있다. 공부하는 입장에서 이해하기 쉬우라고 내가 적은것이기 때문에... 오류라면 수정하겠다)
그 후 stack 메모리에는 String 자료형의 value 라는 이름을 가진 객체가 주소값("0"이라는 메모리가 저장된) 을 참조한다고 기록한다.
자 그럼 여기까지 기본 이론을 기억한 뒤 call 에 대해 들어가보자.
1. Call by Value
이름 그대로, value, 값을 불러온다. 라는 의미를 가졌다. 자바는 그 구조는 다를지언정 모두 이러한 값을 불러오는 형태로 이루어져 있다.
1-1 Call By Value - Primitive Data types
가장 많이 인용되는 swap 을 예시로 들어보겠다.
Class CallByValue{
public void swap(int x, int y) {
int temp = x;
x = y;
y = temp;
}
public static void main(String[] args) {
int a = 10;
int b = 20;
System.out.println("swap() 호출 전 a의 값은 : " + a + ", b의 값은 : " + b);
CallByValue c1 = new CallByValue();
c1.swap(a, b);
System.out.println("swap() 호출 후 a의 값은 : " + a + ", b의 값은 : " + b);
}
}결과는 다음과 같다. swap 메소드를 사용했음에도 불구하고 값은 변하지 않는다.
호출 전 a의 값은 : 10, b의 값은 : 20
호출 후 a의 값은 : 10, b의 값은 : 20왜냐하면 swap 이라는 메소드의 매개변수는 int, 즉 원시 자료형이기 때문에 Stack 메모리에만 저장된다.
그리고 Stack 메모리는 해당 메소드의 사용이 끝남과 동시에 삭제된다.
과정을 시각화하면 아래와 같다.
1단계

main에서 int a, int b라는 지역변수가 생성된다. 이 원시형 변수는 stack 메모리의 main 영역에만 저장된다.

CallByValue 라는 클래스를 c1 이라는 객체이름(유저가 정의한 이름)으로 만들었다. c1이라는 객체는 참조 자로형으로써 heap 메모리에 저장된다. 그리고 stack 메모리의 main 영역에는 heap 메모리의 주소값이 저장된다. #000은 데이터값이 아니라 heap 메모리의 주소값이다.

c1.sawp(a,b) 를 통해 sawp 메소드를 불러왔다.
이 때, stack 메모리에는 main 영역과는 또 다른 swap 영역이 만들어진다. 그리고 swap 영역에서 int x와 int y라는 지역변수가 생성되었다.
x와 y라는 매개변수에는 c1.swap(a,b)에 적혀진 a와 b라는 전달인자의 값이 복사된다.
즉 stack - main 의 int a 값 과 stack - swap int a(x) 값은 서로 다른 폴더 안에 있는 값이라는 의미이다.
따라서 swap 메소드가 실행되면서
x = 20가 되고, y = 10이 되었다 할 지라도.


c1.swap(a,b)의 다음행인 System.out.println(a,b) 가 실행되는 순간
stack 메모리의 swap 영역은 사용이 다 되었기 때문에 메모리에서 삭제된다.
더 쉽게 이해할 수 있도록 비유하자면
컴퓨터 바탕화면에 main 이라는 폴더가 생성되었고, int a, int b 라는 이름의 텍스트 파일을 만들었다.
a라는 텍스트 파일 안에는 10이 쓰여있었고, b라는 텍스트 파일 안에는 20이 쓰여있었다.
그런데 바탕화면에 swap 이라는 폴더를 하나 더 만들고, a와 b라는 텍스트 파일 복사해서 붙여넣기 하였다.
그 후 swap 폴더 안에 있는 a=x 텍스트 파일에 값을 20으로 고쳤고, b=y 텍스트 파일에 값을 10으로 고쳤다.
그런데 swap 폴더가 불필요해져서 swap 파일을 휴지통으로 버렸다.
마지막으로 main 폴더의 a 라는 파일과 b라는 파일의 쓰여진 값을 열어보니 여전히 a=10이었고, b=20이었다.
결과적으로 main 폴더의 값은 변화하지 않은 것이다. 왜냐하면 메소드, 즉 폴더가 달랐기 때문이다.
1-2 Call by Value - Non-Primitive Data Types(Refrences Data Types)
그렇다면 어떤 방법을 사용해야 main 폴더 안에서 다른 폴더 안의 값을 변화시켜줄 수 있을까?
public class CallByValue_2 {
int value;
private CallByValue_2(int i){
this.value = i;
}
private void swap(CallByValue_2 x, CallByValue_2 y){
int tem = x.value;
x.value = y.value;
y.value = tem;
}
public static void main(String[] args) {
CallByValue_2 a = new CallByValue_2(10);
CallByValue_2 b = new CallByValue_2(20);
System.out.println("swap() 호출 전 a의 값은 : " + a.value + ", b의 값은 : " + b.value);
a.swap(a, b);
System.out.println("swap() 호출 후 a의 값은 : " + a.value + ", b의 값은 : " + b.value);
}
}결과를 보니 swap 전후로 값이 바뀌었다.
swap() 호출 전 a의 값은 : 10, b의 값은 : 20
swap() 호출 후 a의 값은 : 20, b의 값은 : 10
가장 간단한 방법은 main과 swap가 작동하는 클래스에 전역변수를 생성하는 것이다.

이 그림을 보면, 원시 자료형 int value 가 생성되는 stack 메모리 영역은 main stack 메모리 영역을 포함하는 전역변수 영역이다. 그리고 이 전역변수는 main 메모리가 작동 중일때에는 항상 존재한다.
그 후 main stack 메모리에서 CalllByValue_2 라는 클래스를 객체이름 a, 객체이름 b로 각각 생성했다. 그리고 a에는 전달인자 10를 전달하였고, b에는 전달인자 20을 전달했다.
이 말은 즉, CallByValue_2 에서 int value = 10 이라는 값을 가진 객체의 이름을 a라고 정의하여 생성했고. CallByValue_2 에서 int value = 20 이라는 값을 가진 객체의 이름을 b라고 정의하여 생성했다는 의미이다.
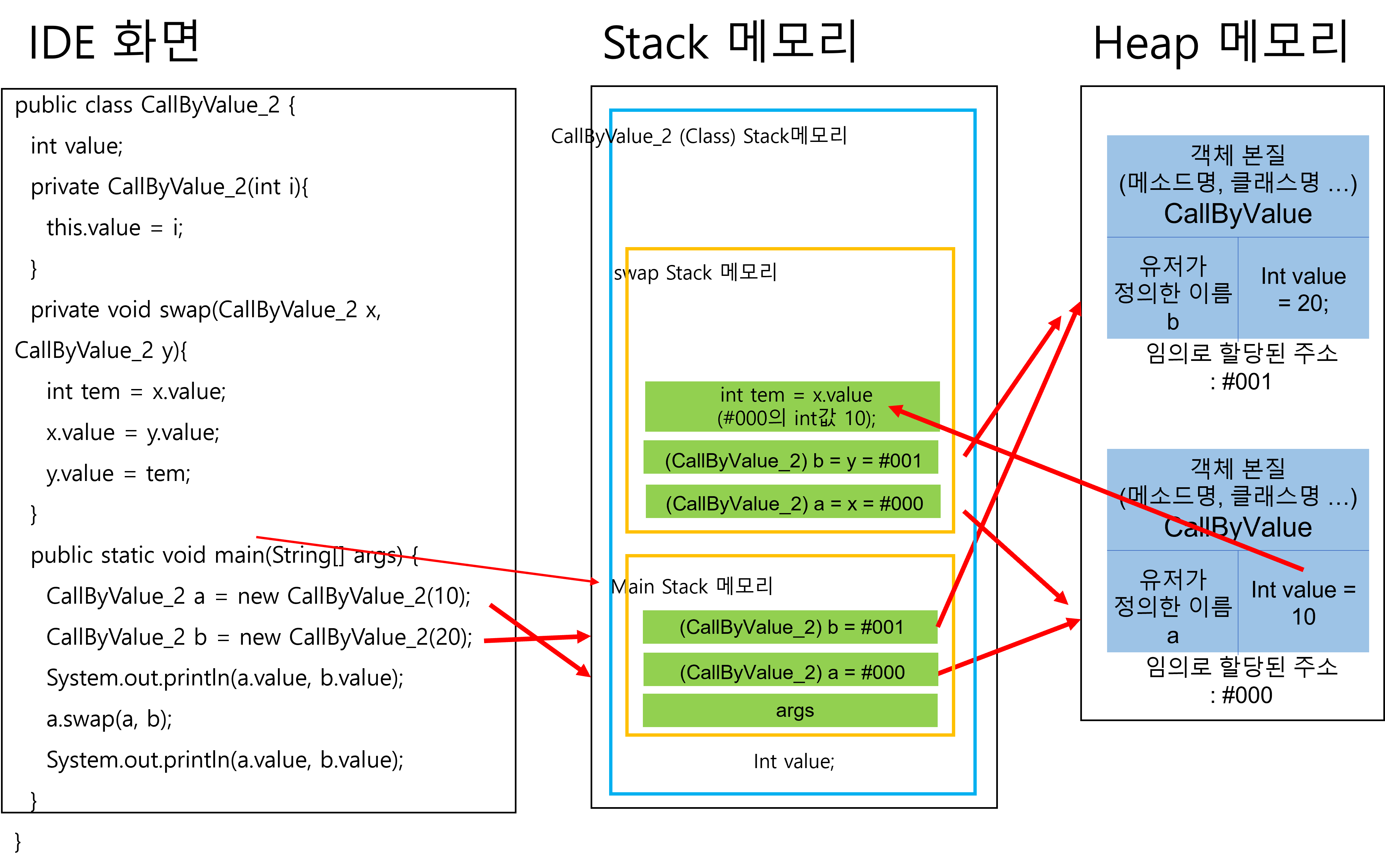
1-1와 동일하게 swap 메소드를 실행시켰다. 하지만 다른 점은 swap 메소드의 매개변수가 원시 자료형이 아니라, 참조 자료형이라는 것이다.
자료형 정리를 하며 기술하였듯, 참조 자료형을 매개변수로 받을 때에는 값을 받는 것이 아니라 값이 저장된 주소를 복사하여 저장한다.
즉 그림과 같이 main stack 메모리가 생성되며 만들어진 heap 메모리 의 주소와 데이터를 swap 메모리도 똑같이 복사하여 사용한다는 의미이다.
그 후
swap 메소드 내에서만 작동하는 int 원시 자료형의 tem 라는 이름을 가진 자료형을 만들었고, 그 안에 x.value, 즉 x라고 사용자가 정의한 이름을 가진 CallByValue_2의 value 값이 복사되어 저장된다.


x.value = y.value ; 즉 x라 명명한 CallByValue_2의 int value = 10; 을
y라 명명한 CallByValue_2의 int value = 20; 로 바꾸겠다는 의미이다. 이 변경은 swap 메모리 내에서만 이루어지는 것이 아니라 그림과 같이 heap 메모리에서 이루어지는 변화이다. 이 점이 1-1의 원시 자료형과의 가장 큰 차이점이다.
원시 자료형의 경우 swap 메모리의 사용이 모두 종료되었을 때, swap 메모리가 삭제되면서 원시 자료형 역시 삭제되었다.
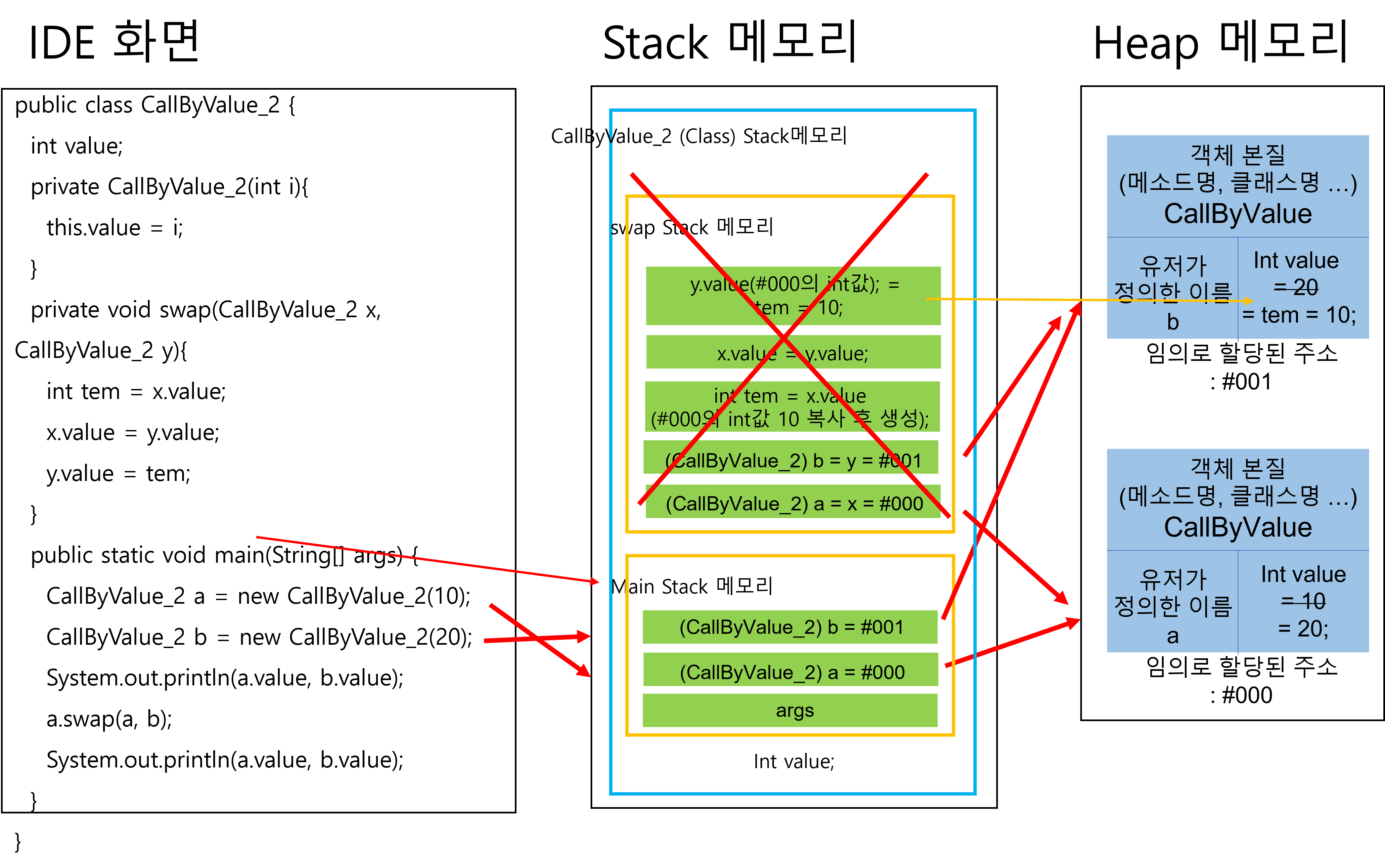
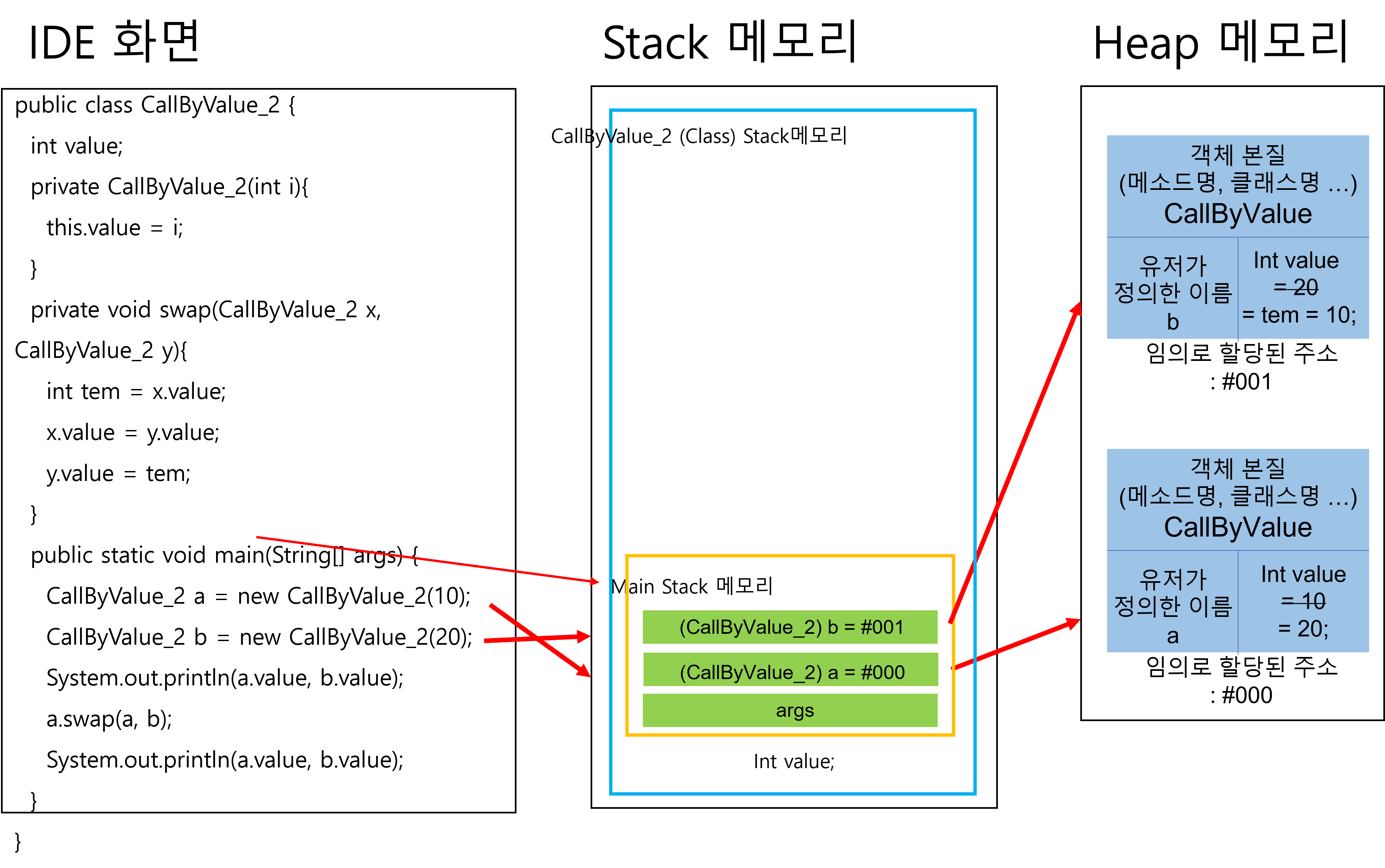
하지만 참조 자료형은 stack 메모리에는 주소값만이 저장되어 있을 뿐이고, 실질적인 값은 heap 메모리 안에 담겨있기 때문에 swap 메모리가 삭제된다 할지라도 이미 heap 메모리의 값은 변화된 상태로 유지된다.
그렇기 때문에 오른쪽의 그림처럼 swap 메소드의 작동이 종료된 후,
a.value, b.value 를 println 하게 되면 heap 메모리 영역 안에서 변화된 데이터 값이 똑같은 주소를 타고 출력되어진다는 의미이다.
'Java' 카테고리의 다른 글
| [Java] StringBuilder 가 필요한 이유, String의 불변객체 (0) | 2022.02.07 |
|---|---|
| [Java] 기초 문법 데이터 입력 및 형 변환, indexOf (0) | 2022.02.07 |
| [Java] 상수집합 enum 의 활용 (0) | 2022.01.07 |
| [Java] BOJ 8958번 관련 String -> char 자료형 변환 (0) | 2022.01.07 |
| [Java] Flag 란? (0) | 2022.01.07 |




